Clojure Performace and the Billion Row Challenge
January 21, 2024 -I recently discovered The One Billion Row Challenge and thought i'd give it a shot using Clojure. TLDR: the solution I ended up with is ~41% faster than the Java baseline provided by the challenge.
The problem is described as:
Write a Java program for retrieving temperature measurement values from a text file and calculating the min, mean, and max temperature per weather station. There’s just one caveat: the file has 1,000,000,000 rows!
The text file has a simple structure with one measurement value per row:
Hamburg;12.0
Bulawayo;8.9
Palembang;38.8
St. John's;15.2
Cracow;12.6
The challenge has a GitHub repo with submissions and leaderboards.
For most of this post i'll be using measurements against 100 million rows because 1 billion takes too long to test solutions, but I will have results on the full data set at the end of this post.
When I run the provided Java baseline on my machine (a Mac mini with a 6 core Intel Core i5 and 16GB of RAM) to establish a baseline I get:
$ time ./calculate_average_baseline.sh
20.80s user 0.65s system 102% cpu 20.948 total
So we are trying to beat roughly 21 seconds.
To simplify the examples, I'm not actually calculating the average, but the data is there to do so, and it would be relatively straightforward/fast as there are only 413 weather stations in the resulting data set.
Attempt 1: 1 minute 57 seconds
This is a relatively straightforward Clojure implementation. But with a 1:57 runtime, not at all competitive with the 21 second baseline.
(ns attempt1)
(defn do-calc [acc row]
(let [[station measurement] (clojure.string/split row #";")
measurement (Double/parseDouble measurement)
station-data (get acc station {:min measurement :max measurement :sum 0.0 :count 0})
new-data (-> station-data
(update :min #(min % measurement))
(update :max #(max % measurement))
(update :sum #(+ % measurement)) ;; This potentially could overflow, but ignoring for the purposes of this blog post
(update :count inc))]
(assoc acc station new-data)))
(defn run [_opts]
(with-open [rdr (clojure.java.io/reader "./measurements.txt")]
(->> (line-seq rdr)
(reduce do-calc {}))))
Lets profile the code with clj-async-profiler.
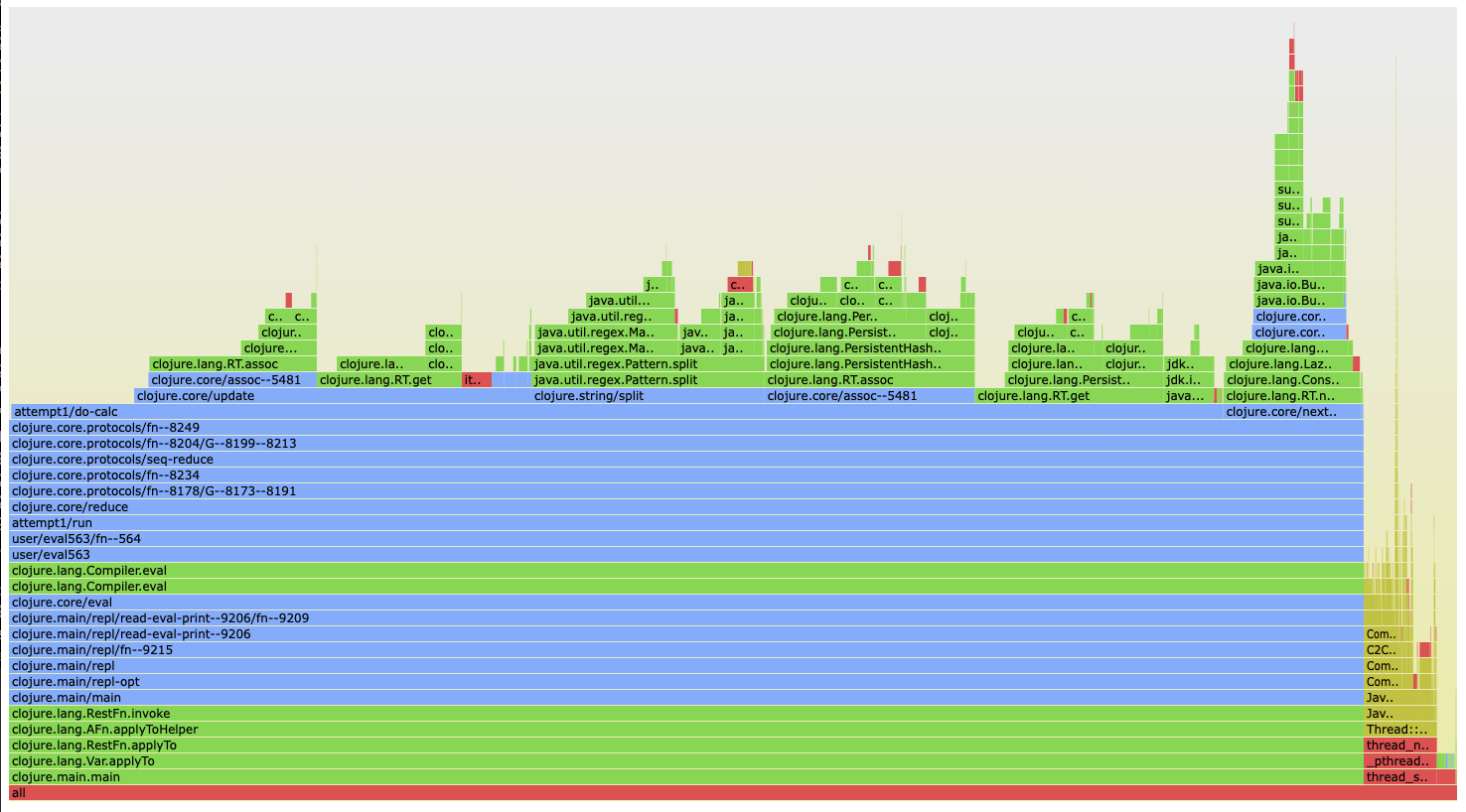
It looks like a lot of time was spent in Clojure functions like clojure.core/update, clojure.string/split, and clojure.core/assoc etc
Attempt 2 - 1 minute 37 seconds
Lets try using a transient map for the accumulator in the reduce function
(ns attempt2)
(defn do-calc [acc row]
(let [[station measurement] (clojure.string/split row #";")
measurement (Double/parseDouble measurement)
station-data (get acc station {:min measurement :max measurement :sum 0.0 :count 0})
new-data (-> station-data
(update :min #(min % measurement))
(update :max #(max % measurement))
(update :sum #(+ % measurement))
(update :count inc))]
(assoc! acc station new-data)))
(defn run [_opts]
(with-open [rdr (clojure.java.io/reader "./measurements.txt")]
(->> (line-seq rdr)
(reduce do-calc (transient {}))
(persistent!))))
Better, but at 1:37, not much better! Even though we're using a transient map as an accumulator in the reduce, we're still using persistent maps as values in the transient map.
We could try using a transient map with transient maps as keys, but given how transients work in practice that approach seems fraught with peril.
Attempt 3 - Did not finish
Lets try using a Java array to store results instead of a Clojure persistent hash map.
(ns attempt3)
(defn do-calc [acc row]
(let [[station measurement] (clojure.string/split row #";")
measurement (Double/parseDouble measurement)
station-data (get acc station (double-array [measurement measurement 0.0 0.0]))
min-measurement (aget station-data 0)
max-measurement (aget station-data 1)
sum-measurement (aget station-data 2)
count-measurement (aget station-data 3)]
(aset station-data 0 (min min-measurement measurement))
(aset station-data 1 (max max-measurement measurement))
(aset station-data 2 (+ sum-measurement measurement))
(aset station-data 3 (+ count-measurement 1.0))
(assoc! acc station station-data)))
(defn run [_opts]
(time
(with-open [rdr (clojure.java.io/reader "/Users/wtf/src/open-source/1brc/measurements.txt")]
(->> (line-seq rdr)
(reduce do-calc (transient {}))
(persistent!)))))
This one was incredibly slow, I had to force quit it before it finished. What is going on here?
If we add the expression
(set! *warn-on-reflection* true)
and rerun, we see a number of lines on stdout that look like:
Reflection warning, attempt3.clj:9:25 - call to static method aget on clojure.lang.RT can't be resolved (argument types: java.lang.Object, int).
Reflection in the Java interop is incredibly slow! Let fix that.
Attempt 4 - 1 minute 6 seconds
We can add type hints to the previous solution like so:
(ns attempt4)
(set! *warn-on-reflection* true)
(defn do-calc [acc ^String row]
(let [[station measurement] (clojure.string/split row #";")
measurement (Double/parseDouble measurement)
station-data ^doubles (get acc station (double-array [measurement measurement 0.0 0.0]))
min-measurement (aget station-data 0)
max-measurement (aget station-data 1)
sum-measurement (aget station-data 2)
count-measurement (aget station-data 3)]
(aset station-data 0 ^double (min min-measurement measurement))
(aset station-data 1 ^double (max max-measurement measurement))
(aset station-data 2 ^double (+ sum-measurement measurement))
(aset station-data 3 ^double (+ count-measurement 1.0))
(assoc! acc station station-data)))
(defn run [_opts]
(with-open [rdr (clojure.java.io/reader "/Users/wtf/src/open-source/1brc/measurements.txt")]
(->> (line-seq rdr)
(reduce do-calc (transient {}))
(persistent!))))
This one is about 30 seconds better than attempt 2, but still significantly slower than the 21 second Java baseline.
Attempt 5 - 45 Seconds
Lets try some optimizations: manually loop instead of reduce, use Java's String split instead of clojure.string/split and don't destructure the results.
(ns attempt5)
(set! *warn-on-reflection* true)
(defn do-calc [acc ^String row]
(let [split-row (.split row ";")
station ^String (aget split-row 0)
measurement ^String (aget split-row 1)
measurement (Double/parseDouble measurement)
station-data ^doubles (get acc station (double-array [measurement measurement 0.0 0.0]))
min-measurement ^double (aget station-data 0)
max-measurement ^double (aget station-data 1)
sum-measurement ^double (aget station-data 2)
count-measurement ^double (aget station-data 3)]
(aset station-data 0 ^double (min min-measurement measurement))
(aset station-data 1 ^double (max max-measurement measurement))
(aset station-data 2 ^double (+ sum-measurement measurement))
(aset station-data 3 ^double (+ count-measurement 1.0))
(assoc! acc station station-data)))
(defn run [_opts]
(let [reader (java.io.BufferedReader. (java.io.FileReader. "./measurements.txt"))]
(loop [line (.readLine reader)
acc (transient {})]
(if line
(recur (.readLine reader) (do-calc acc line))
(persistent! acc)))))
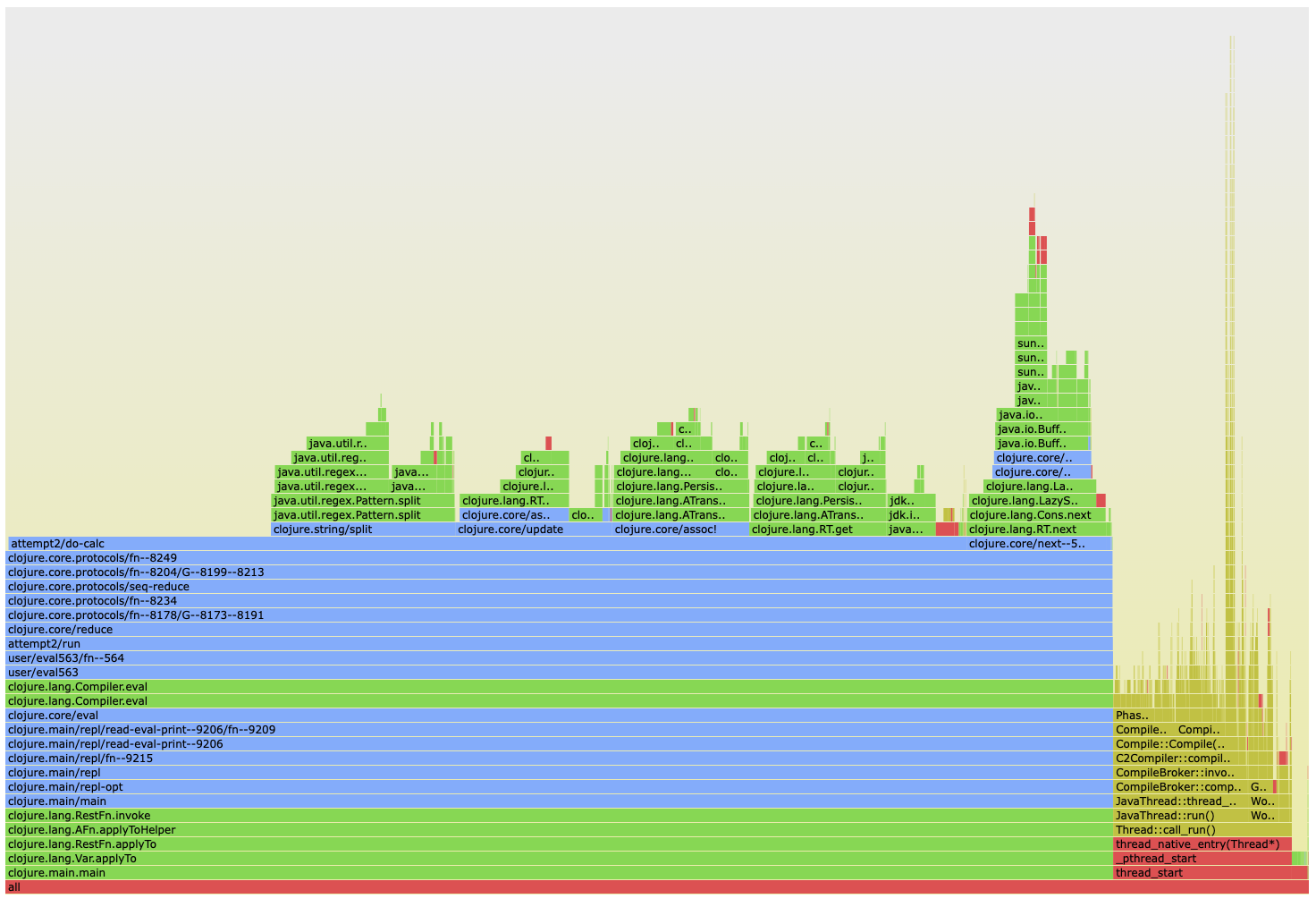
Around 20 seconds faster, but we're still twice the runtime of the Java baseline!
Looking at a flamegraph we seem to be spending a lot of time in calls to clojure.lang.RT.get and clojure.core/assoc!
Attempt 6 - 30 seconds
Lets try replacing the transient Clojure hash map in the accumulator with a java.util.HashMap
(ns attempt6)
(set! *warn-on-reflection* true)
(defn do-calc [^java.util.HashMap acc ^String row]
(let [split-row (.split row ";")
station ^String (aget split-row 0)
measurement ^String (aget split-row 1)
measurement (Double/parseDouble measurement)
station-data ^doubles (.getOrDefault acc station (double-array [measurement measurement 0.0 0.0]))
min-measurement ^double (aget station-data 0)
max-measurement ^double (aget station-data 1)
sum-measurement ^double (aget station-data 2)
count-measurement ^double (aget station-data 3)]
(aset station-data 0 ^double (min min-measurement measurement))
(aset station-data 1 ^double (max max-measurement measurement))
(aset station-data 2 ^double (+ sum-measurement measurement))
(aset station-data 3 ^double (+ count-measurement 1.0))
(.put acc station station-data)
acc))
(defn run [_opts]
(let [reader (java.io.BufferedReader. (java.io.FileReader. "./measurements.txt"))]
(loop [line (.readLine reader)
acc (java.util.HashMap.)]
(if line
(recur (.readLine reader) (do-calc acc line))
acc))))
At 30 seconds we're getting toward respectable compared with the baseline. However we've gotten so deep into Java interop and away from idiomatic Clojure code that it would probably make more sense to just write this solution in pure Java.
Also, maybe we should next try a solution that isn't effectively single threaded.
Attempt 7: core.async
Taking the code from attempt 6, but using core.async to fanout to multiple channels ultimately did not go anywhere, we're largely CPU bound and core.async seemed to just add overhead.
I'm tempted to try this again in the future to see if I can make it faster. Not sharing the code as I never got it to a place I was happy with and didn't want to spend time optimizing a solution that was unlikely to be the best.
Attempt 8: Reducers - 27 seconds
This time we'll go back to using code that looks more like typical Clojure and leverage reducers. The fold function reduces a collection using a (potentially parallel) reduce-combine strategy. Meaning I can easily use all 6 cores on my machine!
One problem with fold is that it should be used when source data can be generated and held in memory, which is not necessarily the case with billions of records. However, we can use the iota library to create a seq of the file which is tuned for reducers and can handle files larger than available memory.
(ns attempt8
(:require [clojure.core.reducers :as r]
[iota :as iota]))
(set! *warn-on-reflection* true)
(defn merge-counts
([] {})
([x y] (merge-with (fn [[x-min x-max x-sum x-count]
[y-min y-max y-sum y-count]]
[(min x-min y-min) (max x-max y-max) (+ x-sum y-sum) (+ x-count y-count)]) x y)))
(defn do-calc
([acc ^String row]
(let [[station measurement] (clojure.string/split row #";")
measurement (Double/parseDouble measurement)
[cur-minimum cur-maximum cur-sum cur-count] (get acc station [measurement measurement 0.0 0])
new-data [(min measurement cur-minimum) (max measurement cur-maximum) (+ measurement cur-sum) (inc cur-count)]]
(assoc acc station new-data))))
(defn run [_opts]
(->> (iota/seq "./measurements.txt")
(r/fold merge-counts do-calc)
println))
27 seconds isn't bad for a first attempt with this approach.
Attempt 9: Reducers with optimizations - 9.6 seconds
Lets try the previous attempt but with optimizations used in previous attempts.
(ns attempt9
(:require [clojure.core.reducers :as r]
[iota :as iota]))
(set! *warn-on-reflection* true)
(defn merge-counts
([] (java.util.HashMap.))
([^java.util.HashMap x
^java.util.HashMap y]
;; Convert to clojure.lang.PersistentHashMap so we can use merge-with.
;; Probably could be optimized to directly merge the Java HashMaps
;; but reducer merges should be relatively infrequent, so probably not worth optimizing
(let [x (into {} x)
y (into {} y)
^clojure.lang.PersistentHashMap result (merge-with (fn [[x-min x-max x-sum x-count]
[y-min y-max y-sum y-count]]
[(min x-min y-min) (max x-max y-max) (+ x-sum y-sum) (+ x-count y-count)]) x y)]
(java.util.HashMap. result))))
(defn do-calc
([^java.util.HashMap acc ^String row]
(let [split-row (.split row ";")
station ^String (aget split-row 0)
measurement ^String (aget split-row 1)
measurement (Double/parseDouble measurement)
[cur-minimum cur-maximum cur-sum cur-count] (.getOrDefault acc station [measurement measurement 0.0 0])
new-data [(min measurement cur-minimum) (max measurement cur-maximum) (+ measurement cur-sum) (inc cur-count)]]
(.put acc station new-data))
acc))
(defn run [_opts]
(->> (iota/seq "/Users/wtf/src/open-source/1brc/measurements.txt")
(r/fold 1028 merge-counts do-calc)
println))
9.6 seconds isn't super fast, but we are now handily beating the 21 second Java baseline.
Results with 1 Billion rows
Instead of using 100 million rows, we'll finally run against the full 1 billion row dataset:
| Entry | Results |
|---|---|
| Java Baseline | 3:47 |
| Mine | 2:13 |
| Best competition entry | 0:16 |
We're about a minute faster than the Java baseline.
But we're nowhere close to the 16 second runtime of the best Java entry (or at least best as of the time of writing). That entry describes itself as:
Simple solution that memory maps the input file, then splits it into one segment per available core and uses sun.misc.Unsafe to directly access the mapped memory. Uses a long at a time when checking for collision.
It appears to be using sun.misc.Unsafe to mostly avoid overhead of using java.lang.String (which i'm not sure if it would break if weather stations could contain UTF-8 characters larger than one byte), a custom hash map implementation, a custom implementation of Java's Integer/parseInt, etc. Definitely an impressive runtime, but I almost wonder if it would make more sense to just use C++ with that approach.
Though there are some other interesting entries that are fast and don't use sun.misc.Unsafe like this one that uses the jdk.incubator.vector package to take advantage of Single Instruction Multiple Data (SIMD) parallelism.
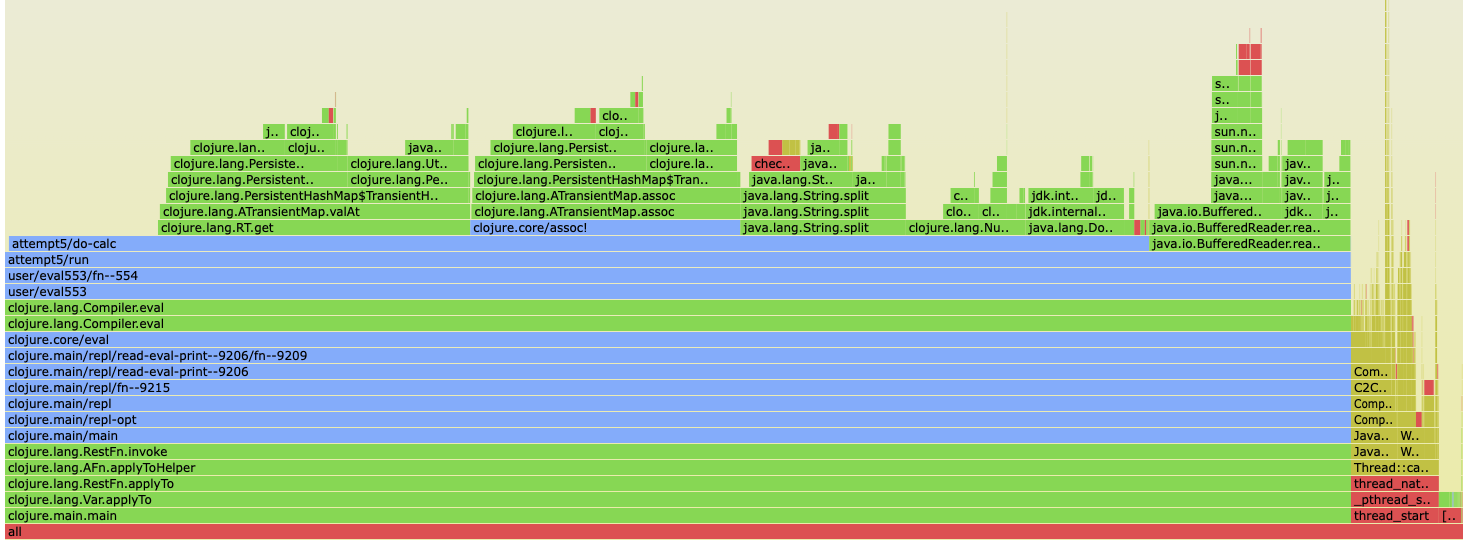
Next steps
There are a number of optimizations I could look at to try to get a better time. Looking at a flame graph I think there is a good amount of overhead in the iota code that could be bypassed with a custom solution memory mapping the file into a number of chunks equivalent to the number of processors, but ultimately i'm pretty happy with what I came up with over the course of a Saturday afternoon and probably will call it here.